Four Steps to Analytics Governance


This blog will guide you through a step-by-step process for beginning to govern your data in the cloud, making it easily understandable and accessible for analytics projects across your organisation.
There are four key steps that we will introduce here in brief. If you would like to deep dive into any of these topics, please sign up for any or all of our upcoming Cloud Analytics Governance webinar series which will go through these in greater detail:
-
Harvest Technical Metadata
-
Establish Analytics Governance Framework
-
Connect and Enrich Business and Technical Metadata
-
Democratize Data for Analytics
Harvest Technical Metadata
The first step towards governing your data in the cloud is gaining understanding about what data you have and where it is held. For most companies this may feel almost impossible, with tens or hundreds of systems in use, each one holding more data than the last, and a lot of it poorly named—how can you begin to know where it all is and what it all means? Well, luckily this is no longer a manual task but can be heavily supported by artificial intelligence and machine learning—but there are still a few decisions for you to make.
First up, it is worth prioritizing the systems in your data landscape. You may end up wanting to scan and catalog all of them but—at least for the short term—there are probably a few which stand out as holding the most important data. Once you have your shortlist, you can think about what type of data you expect to find within them (e.g., customer, product, employee) and what you would like to automatically classify. Classification rules can then be applied to auto-tag your technical metadata as it is catalogued. Then comes the technical piece of creating a source, configuring the scan to run just as you like it, running it, and reviewing the results. You can decide just how much control you would like to give the machine, setting a confidence threshold for automatically tagging metadata and reviewing the matches that don’t quite meet that threshold.
Establish Analytics Governance Framework
While the technical heavy lifting is being taken care of by AI/ML, you will want to spend some time thinking about the framework that will hold together your analytics governance program. For one thing, what are the key assets types you want to govern?
You might be interested in defining these key items:
-
Business Terms & Metrics
-
Policies & Terms of Use
-
Processes
-
Systems
-
and even AI/ ML Model themselves
To do so, you will need to gather the right people with the subject matter expertise to create these definitions and think carefully about how they link together, often in hierarchical structures. For instance, if you decide customer data elements are critical to the success of your analytics program, you might want to define terms such as customer address, age, and gender, and group these together in a customer descriptors subdomain. Similarly, you may decide that certain terms of use for data apply only to personal data and can hierarchically build those out to show the link.
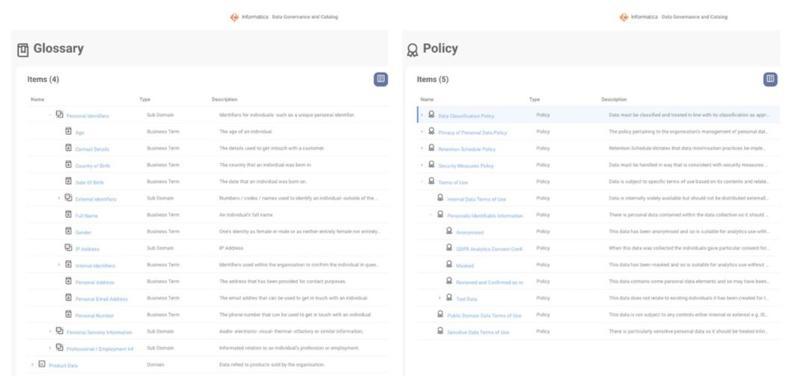
Figure 1. Glossary Hierarchy and Terms of Use Hierarchy
In this example, we can see that the permissive terms of use can in fact be used to negate restrictive policies. For instance, if you have a restriction on sharing personal data because of privacy regulations you might choose to set up a condition that allows you to democratise this data anyway. By creating anonymised versions of datasets, or even restricted samples from those who have given content analytics, you can ensure that data can still be used for analytics even if the data includes PII. Building privacy ideas into your governance program is what privacy regulations are all about, and if you are careful, you can ensure they do not limit your analytics progress any more than necessary.
Connect and Enrich Business and Technical Metadata
The third step on your journey to Cloud Analytics Governance is to ensure that you are connecting all of your hard work! The technical metadata that you have extracted takes on so much more meaning and value when connected to the business content and the business context is grounded in reality when connected to physical data. The good news is that some of this process can also be automated. Meaning that, once you have built your glossary, you can select to turn on glossary association for your next scan and the automated engine will not just tag your metadata with classifications based on different rules, but also name-match the metadata to your entire glossary, linking technical columns to the business definitions you have carefully described.
There will also be some further connections you’ll want to build in. All of these key assets are interconnected, and the more you expose the connections, the more context and value you will get out of your analytics governance projects. The concepts you carefully defined in your glossary will be subject to some of your policies and used in some of your processes—building up these relationships allows you to create the full picture. The columns that have been tagged will also have their own innate quality, which can be measured and recorded. By tying not just definitions but related policies, quality, and process to data, you will begin to understand when you can and can’t use it—as well as when you shouldn’t even want to!
Democratise Data for Analytics
The single biggest driver for governance has shifted away from being compliance-based and towards being supportive of sharing data, most often for analytics purposes. Once you have laid the foundations for analytics governance by building a catalogued, connected understanding of your data landscape, you can begin to share data across your organisation without concern, knowing that it is well-catalogued, governed and connected to the appropriate policies. To do this, you will want to create the best possible experience for your data consumers by supplying them with the building blocks for an intuitive data access request process. Ideally, these include:
-
Broad categories of data to browse through
-
Specific, templated methods of delivery
-
Pre-packaged, enriched data collections
Each of these elements should be carefully considered as they will contribute to the ease of experience for data consumers. Categories should be broad to allow for distinction between them—customer, product, organisational etc. Delivery templates should direct your end users to the best, most efficient ways of receiving data, often these will be related to cloud-based applications such as data lakes or online repositories where the only requirement for access will be an update to user permissions. Finally, the data collections themselves should be enriched with as much useful information as possible, and grouped together in useful combinations —for example, customer order data with product data for a holistic view of purchases. Once you set your data marketplace up in this way, all you’ll need to do is keep it moving with data owners and technical owners promptly responding to ensure consumers get the data they need, in the time frame they need it!
If you are ready to launch an Analytics Governance initiative in the cloud in your organisation and would like to hear more about any of the ways Informatica can help, please check out the Cloud Data Intelligence Summit to learn more or contact us on [email protected] .
Author:
Kate Amor, Data Governance Marketing Manager, Informatica